上一篇我們已經完成心血管疾病資料的訓練並且產生model檔. 本篇我們再來加入MLflow的功能, 練習一下要怎麼將每次訓練的參數、metric與model記錄起來.
在心血管疾病的範中, Tracking功能仍然使用MLFlow進行說明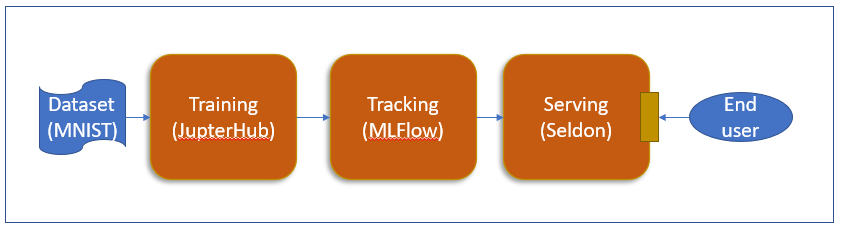
這份notebook可以從下方連結下載:
https://github.com/masonwu1762/ithome-ironman
在上一篇notebook的最後我們繼續加上下列內容
首先我們先裝mlflow, 好讓我們可以在notebook呼叫mlflow的程式庫.
!pip install mlflow
接著指mlflow import進來
# Import mlflow
import mlflow
import mlflow.sklearn
接著我們要呼叫set_tracking_uri函式並設定MLFlow的IP與port, 這樣才能我們才能將想要log起來的資料傳到指定的MLFlow server.
在Day7已安裝好MLFlow server , 而且在Day8的內容中已說明過MLFlow可支援的四種uri的格式, 請再參考Day7與Day8的內容
mlflow.set_tracking_uri("http://172.23.180.10:30534")
然後設定做這次訓練的主題, 在MLflow是稱為experiment. 因為我們這次是使用心血管疾病的資料執行訓練, 所以我們把experiment的名稱叫做cardiovascular_disease
mlflow.set_experiment("cardiovascular_disease")
最後我們就要把之前訓練過程的parameter、metric與model記錄起來.
然後繼續加上下列內容
with mlflow.start_run(run_name="jack-run-1"):
mlflow.log_param('split_rate', split_rate)
mlflow.log_metric('precision', precision_score(y_test, predict))
mlflow.log_metric('recall', recall_score(y_test, predict))
mlflow.log_metric('accuracy', accuracy_score(y_test, predict))
mlflow.sklearn.log_model(model, artifact_path="xgb-model")
我們來執行二次. 第一次是將split_rate設定為0.2, 也就是訓練資料占80%, 而測試資料占20%
請將cell 16 的split_rate設定為0.2
split_rate = 0.2
再將run name設定為jack-run-1
with mlflow.start_run(run_name="jack-run-1"):
我們重新執行一訓練, 等整個notebook執行完成之後, 再去MLFlow看一下結果, 應該會看到有一筆記錄被記下來了, 如下圖: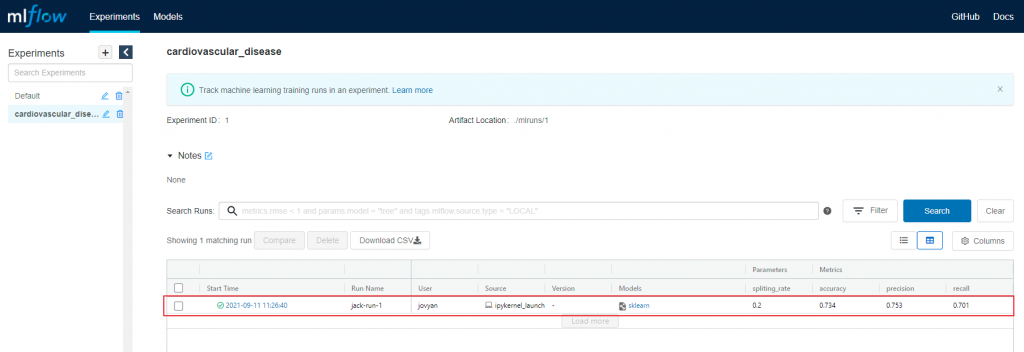
接下來再來執行第二次, 我們把 cell 16的 split_rate設定為0.3
split_rate = 0.3
再將run name設定為jack-run-2
with mlflow.start_run(run_name="jack-run-2"):
然後我們再來執行一次notebook. 然後可以在MLFlow上看到二筆資料.
使用這種方式就可以將每次執行訓練的parameter、metric與model記錄記來

